Original: Feb. 15 - 2024
Last edited: Feb. 17 - 2024
Creating Grammarly from scratch
Disclaimer: This Grammarly replica is built in Danish. The exact modules built will be specific to Danish, but the methodology and implementation should be transferable to other languages.
Backend | Frontend | Word add-in | Datasets
To my knowledge, no one has tried to create a complete replica of Grammarly for another language and document the process for others to learn from. I couldn't find anyone at least. So I decided to try this out myself. It's not easy, but possible to get it to a stable and valuable state.
This will be a long post. I tried to divide it into chapters as much as possible. Read what you need, and skip what does not interest you. Here we go.
When reading this, please keep in mind that the project took ~18 months to complete. So if you think some parts seem quickly done, you can safely assume it took a month or two to execute :-).
0. The idea
Building a complete replica of Grammarly is not possible and will not be the goal. What I find interesting is trying to rebuild the core functionality to get an idea of how it works. So the main goal here is to figure out how to:
- Make simple checkers to help out with spellchecking, simple grammar rules and punctuation
- Build a bigger model to tackle some problem better (either spellchecking, punctuation or something else)
- Develop a small, simple UI for users to interact with the project
- Hook everything up to work on the web & cloud
1. Where to begin?
Before developing anything, let's define how this project should be built
In real-time, what happened is I developed this complete project without making any considerations around structure, architecture, etc. This was a BIG mistake! So for that reason, let's tackle that issue first, and save 2-3 rounds of complete rewriting of the entire codebase.
The idea is to build each correcter as modules to easily be added, modified, or deleted. But what modules provide value? After researching the topic, one report suggests the main issues (in Danish language) are (in no specific order):
- Punctuation (main "," & ".")
- Capitalization
- Spelling
- Wrong tense
- Lack of subject
- Articles
- Compound words
- Excessive spaces
- Double words
- Clarity?
1.1 Structure and utilities
The idea is to build simple modules to begin with in order to make sure the structure works before creating any substantial modules that then could have to be rewritten. The backend will be built in Python. It could be faster to do in other languages, and that's probably also the case for Grammarly, but this makes it possible to use existing packages to simplify the backend a lot! First, we will tackle:
- Capitalization
- Excessive spaces
- Double words
Before developing any modules, let's build the outside structure. The modules are going to return a list of Errors that they find, so let's start by making such a class. The classes Error and ErrorList are created as some functionality is needed both for each error and also to add lists of errors together (see utils/error_handling.py). The class Error can be summarized in this main method:
def to_list(self, include_type=False):
self.is_healthy()
if self.wrong_word == self.right_word:
print("ALERT: Error has the same wrong and right word, therefore skipped");
print(self.to_finalized_list());
return None
if include_type:
return [self.wrong_word, self.right_word, self.indexes, self.description, self.get_type()]
return [self.wrong_word, self.right_word, self.indexes, self.description]
So what is the type of an error? This helps with the problem of having multiple errors at the same place. Grammarly won't give you multiple errors on the same word - they concat them, so that's what have to do too. The error_concatenator() is a way for us to concat the errors together. This is a tedious, but rewarding process, and converts errors like this:
[
",", "", [18,19],
"There should not be a comma before 'that'", "del_punc"
]
+
[
"paul walker", "Paul Walker", [8,19],
"'Paul Walker' should be capitalized", "add_cap"
]
=>
[
"paul walker,", "Paul Walker",
[8,19],
"There should not be a comma before 'that'. 'Paul Walker' should be capitalized",
"add_cap"
]
Let's now talk about indexing. Some modules have to work on characters, some on words. Another issue is that some modules may depend on other modules before being able to make their predictions. So we need some way of converting from word indexes to character indexes to easily highlight the errors on the front end. And we need those indexes to refer to the input sentence, which could be different from the one each module is correcting.
To achieve this, the IndexFinder class was created. When initialized, the input sentence is given. The IndexFinder is then passed around the modules, where they have the opportunity to change the sentence based on their errors if needed. Whenever needed, word indexes can now be created from whatever sentence the module is using to character indexes for the input sentence.
Before moving on to actually creating the modules, let's get the main script running. It should be fairly easy. Import the modules needed, initialize them, and make them work with a microweb framework like Flask. The index function should look like:
app = Flask(__name__)
CORS(app)
@app.route("/", methods=["POST"])
def index():
data = request.get_json()
input = data["sentence"]
output = correct_input(input)
return jsonify(output)
The correct input function can then correct the input sentence however we want. CORS is needed to make it possible for the frontend to connect to the backend. Flask is properly not the best for a full production environment, but it should work for now. If this were to be deployed and receive proper traffic, this part should probably be improved.
1.2. How hard can it be?
The first module we will create is the excessive spaces. To preserve some space (and your time) I will not go too much into detail about the code. I will explain the thought behind every module and how to achieve the functionality. This module is fairly straightforward. We want to remove leading, consecutive, and trailing spaces. Check all characters from front to back. If a space, suggest to delete. Repeat from back to front. Then check each character. If more than one space, suggest changing to only one space.
Next is compound words. This could be a applied in a sentence like: "I really really like a a cake". This isn't super valuable, but sometimes you won't see these simple errors. Now, there might be times when the same word should appear twice in a row. To find these, you should scrape through a large collection of text. For Danish I used Gigaword, but for English many other options exist including Wikipedia, nltk & Spacy. We will have to scrape through large text chunks multiple times, so make sure to find a proper one. Ideally high quality like from newspapers, research reports, etc.
After scraping through these, save all events where a word occurs twice in a row, and exclude them from checking. We also don't want to correct names, so make the module able to get a list of named entities and exclude them too. That should be it for this module.
The last module in this section is capitalization. This should take in the list of named entities mentioned above. Now go through every word, if the previous word has a full stop, suggest capitalization if not already. If the word is in the list of named entities, suggest capitalization. This module should also suggest to not capitalize words that do not meet the criteria. One important thing to now keep in mind is that this module has to be after punctuation as the sentence might change as a result of that module.
1.3 Named Entity Recognition
Now, as mentioned above, we need to figure out which words are named entities. We also need to figure out each word's part of speech. Lucky for us, this is nothing new and has already been implemented in various NLP libraries, so a quick grab and use should be sufficient to get us going. English models are available at Huggingface, nltk, and Spacy, so it's just a matter of preference.
Take your NER and POS tagger (can be two different like in my case), and run them at the beginning of your main function, so that we can use them later. Check that the NER works as expected in the capitalization and compound words modules.
1.4 Now to the fun part: training models
Or at least close to it. Before training models, we need data. Remember the sources I mentioned earlier? Time to put them to good use. The important thing here is finding not only enough but text of extremely high quality. Go through some of it yourself to make sure it's good i.e extremely low rate of grammatical mistakes.
The dataset we create has to fit the model we choose. The first problem to tackle is punctuation. So before doing anything, we have to figure out the appropriate model to use.
1.5 Choosing the right model
The NLP space of deep learning models is booming, so we have plenty of models to take from. Or at least in English that is. In general, I see two ways of handling this problem (if something else comes to your mind, please reach out to me!)
- Seq-2-seq: You give the model a sentence and the model returns with a sentence with punctuation. The dataset has to be sentence to sentence, and you need A LOT OF data of high quality. Finding the punctuation and returning the index of potential suggestions can be difficult.
- BERT: You give the model a sentence and it returns with a classification. You need less data, but the inference might be slower, so a smaller model is needed for a reasonable compute time, but large enough to have a decent accuracy. (BERT and distilBERT are the only ones available in Danish, but you can use RoBERTa, destilBERT, Electra, etc.)
With Sep-2-sep the results were unreliable and the training time too costly, so I decided to move on with a Danish, pre-trained BERT. The dataset then had to be fairly simple to create. (As of Feb 2024, seq-2-seq might actually be the right solution as the growth in GPTs has been enormous, so definitely check Huggingface out!)
Before creating the dataset, let's decide on the scope. The scope is the size of the sentence that is the input. You give x words to the left, and y words to the right. After the middle word is where you predict the punctuation. In real-time, there is only one way of knowing the right scope -> testing! And that's certainly not cheap. I did small experiments to see what happened. The smaller the scope, the faster the inference, the faster the training, but the lower the accuracy. So it's a fine line.
I initially tested with BERT (I logged most results here), but quickly switched to distilBERT for about 2x faster inference. You generally need more information from the left, but also a bit from the right. To achieve a high accuracy, but still fast inference, 15-5 seems to be the right scope. So given a sentence like this:
Hello, my name is Lucas. I like to train deep neural networks.
The dataset should look like this (here with a scope of 3-3 to show the idea). Remember to delete both capitalization and punctuation as knowing this will skew the accuracy and may not be present when correcting real sentences.
| input | output |
|---|---|
| PAD PAD hello my name is | 1 |
| PAD hello my name is lucas | 0 |
| Hello my name is lucas i | 0 |
| my name is lucas i like | 0 |
| name is lucas i like to | 2 |
| ... | ... |
Hopefully, you get the idea.
1.6 Training
The dataset I used was about 46.000.000 elements long. The authors of BERT state that 2-4 epochs of fine-tuning is best. I found that 2 epochs were enough, with only a small, non-significant (~0.1%) increase in accuracy when training for 3 epochs. This was not worth it compared to the cost, so I decided to stick with 2.
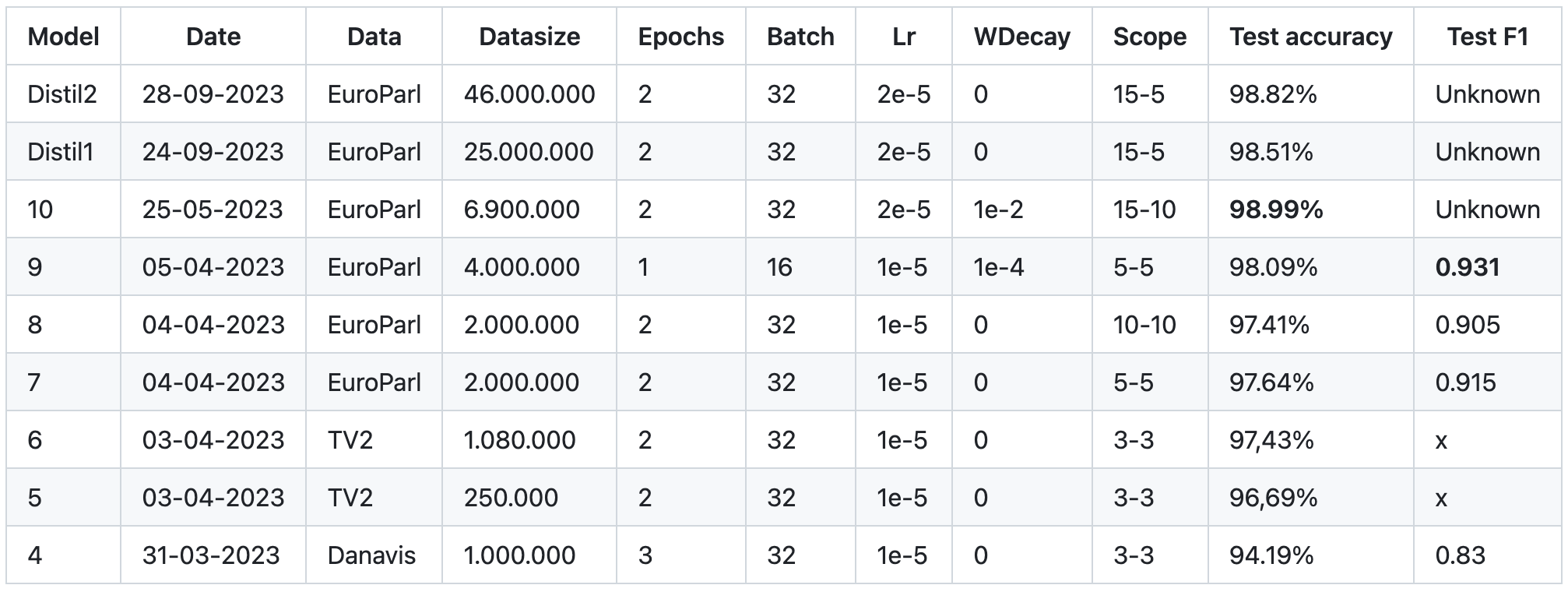
The distilBERT was trained on Jarvislabs renting 6 A100s for ~10 hours totaling ~120 dollars. The script used for training can be found at FineTuneModels/FineTuneBert. This was certainly not the cheapest or best way to do it (As of Feb 2024, there should be cheaper ways to fine-tune such a model with a much smaller training size as well, so give yourself some time to explore the options available), but it got the job done.
1.7 Implementing into a module
Inference is, of course, a bit different from training, but not too difficult to implement. The full module is implemented here. The most important thing is to argmax the outputs of the model as they are from a softmax with 3 values, so the one with the highest value should be the prediction. You have to create the dataset from your input sentence, but besides that is shouldn't be too difficult:
def get_predictions(self, data : string):
dataset, split_indexes = self.get_dataset(data)
tokenized_data = self.tokenizer(dataset, padding=True, truncation=True)
final_dataset = Dataset(tokenized_data)
raw_predictions, _, _ = self.trainer.predict(final_dataset)
maxed_predictions = np.argmax(raw_predictions, axis=1)
return maxed_predictions
1) Create your dataset from your input sentence, 2) tokenize, 3) format into tensor dataset (this can be hard to get right, look at the top of Utilities/model_utils.py to see how I implemented it), 4) run your model, and 5) max the predictions.
1.8 Additional modules
So a few modules are still missing. To cut down on the size of this post (yeah, maybe that's too late 😅?!) I will just quickly cover them.
Wrong tense: This approach was exactly the same as with punctuation. In Danish, the main problem with tense is verbs in present tense have a silent "r" at the end, which can be difficult to hear. To tackle this, a new dataset was created with the verb being unknown. So this time, the dataset will look something like this (with a larger scope than shown here)
| input | output |
|---|---|
| hello my name PAD lucas i | 0 |
| is lucas i PAD to train deep | 0 |
Where the value refers to the form of the verb. This did give some pretty good results:
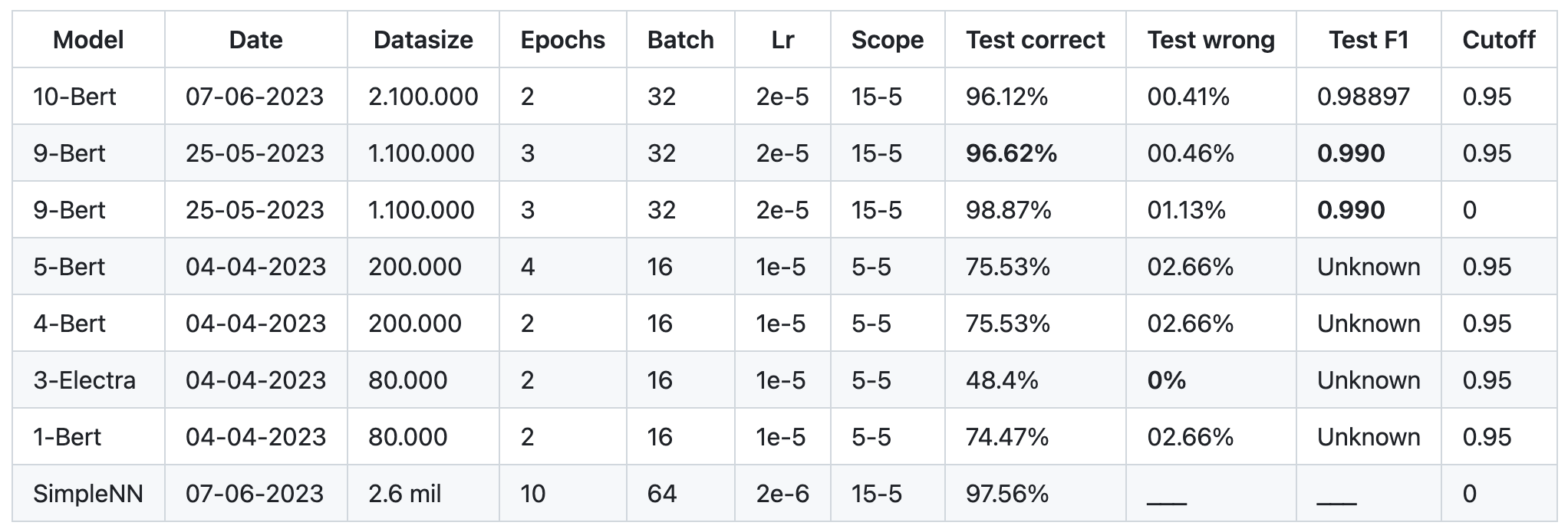
In this case, the amount of wrong predictions was ~1%, which was a bit too high for me. I then only used the prediction if the confidence level (not really confidence in these models, but somewhat an estimate) was above 95% (you get a 2x2 matrix with the first value can be thought of being 'probability' and the second 'confidence'). This decreased the amount of wrong predictions to ~0.4% while only decreasing the accuracy with 2 pp (whoop whoop!!).
Spellchecking is a big project on its own and way too much to cover here. I might do another post on that someday. I tried many different approaches: simple spellcheckers, n-grams, word embeddings, and gpts. I ended up using a mix of a simple spellchecker formula by Peter Norvig (this is btw an amazing read and I would highly recommend it) and the specific issues around Danish spelling allowing me to give good educated guesses on where the issues in the spelling might be.
Lack of subject is more of a modern problem, but I thought this would be fun to investigate. When writing more formal text, such lack of subject should definitely not be present. I didn't really find a satisfying solution to this problem. The main functionality at the moment is checking if the structure of the sentence matches some hard-coded, frequent structures. If so, it's pretty easy to determine if the subject is missing and suggest one.
Articles can be difficult in Danish just as in any other language, the most prominent issue being the difference in when to use a noun as common gender or neuter gender (most languages use masculine and feminine but it's essentially the same point). Thankfully, the POS tagger described earlier takes care of this when analyzing part-of-speech, so it's as simple as finding the information in the POS object and checking that it matches the current sentence.
2. The frontend
Phew, that was tough. Now we need some place for the users to actually try the modules out and to get some data. This could be a website or some add-in somewhere. This has to be deployed somewhere together with the backend.2.1 A simple webpage
There are many different ways of doing this. React or Angular is a way, but I decided to do it in plain html, css & js. It's definitely not the best, but it will do as a simple website for users to test on (the website is originally in Danish, and Google did the translations, so they might not be perfect):

I bought a domain, hooked it up with my Github repo, and launched to site with Github pages. That is the benefit of developing static sites. If I were to use some frameworks, vercel may be a way to host it.
One thing I focused on was continuous corrections and splitting the text into smaller chunks when correcting. Initially, the feedback was that the service was too slow. This was mainly due to the BERT in punctuation, so difficult to optimize. I instead decided to split the input into smaller chunks, so the corrections would come to the user over time. This seemed to improve the user experience. By continuously checking if the text changed, this also allowed the user to change the text and then get feedback in real-time within the text editor in on the webpage.
2.2 Putting it all together
So we need somewhere to host this. The front end is hosted at Github pages for free. There are a few options for the backend. The problem is that it cannot be a function app / lambda function / cloud function depending on if you use Azure, AWS, or GCP, as the models and large dictionaries have to be loaded in for the modules to work. This takes ~15 seconds, so there is no way this would happen for each request.
Renting a VM is what I did. It all fell on Google as they had the lowest prices (~$200 pr. month). I bet you there must be a better solution to this, so there is definitely space for improvement here. Setting up a simple Flask app on a Google VM is relatively easy, but you might be looking for some gcp cli commands to upload new code and put in production, so keep these in mind:
gcloud builds submit --tag _bucket_or_vm_name_
gcloud run deploy --image _bucket_or_vm_name_ --platform managed
Where your _bucket_or_vm_name_ should look something like: 'gcr.io/grammatiktakbackend/index'. Remember to enable cors in the Python script with `CORS(app)` to allow for the front end to send requests. For security reasons, you may want to only whitelist your frontend for requests. When using CGP, this can be done on their platform
2.3 What about drift and accuracy in production?
You may have noticed that at the bottom of the website, there exists an option to give feedback. We also have the issue of drift in production together with the fact that we don't really know how well the modules work. First, a ModuleTracker is made to track each module (time & corrections) on requests and upload to storage just before sending the result back to the front end. For storage I used Google Firestore. It's expensive compared to the storage used, but a flexible, scalable NoSQL database.
For the feedback, to ensure high security, the information is sent to the backend and then to the storage. This is fast to implement as the connection to the storage is already active, and does not increase the cost of the VM, but also a place where optimization should be applied.
One last thing that one could do is to send information about which corrections were accepted or denied when the last correction is handled. With all that out of the way, we can now easily pull data to measure which modules are performing well both in terms of offering value and doing so in an acceptable amount of time. Now it's just about analyzing, then improving, removing or adding modules, and thereby improving the service.
3.1 Word add-in
In addition to the website, I wanted an integrated way of using the service, so I decided to build a Word add-in, just like Grammarly works in Word. The API of Google Docs is insanely slow, so there is no way to implement it in Google Docs, which I initially tried. The word add-in works locally, but I didn't make the effort of making it publicly available. If I had to try again, I think I would build a desktop application that can work with multiple apps. This would offer more flexibility when working with Word, as the add-in framework seems a bit old and outdated.
3.2 High-quality dataset
There do not exist many high-quality Danish datasets, so I spend some time reviewing text myself to use for testing my modules. The training datasets can be created by running files in /DataProcessing. The datasets and dictionaries used by the modules for correcting can be found at /GrammatiktakBackend/Datasets. The testing datasets can be found in the GrammatiktakDatasets repo.
4. Final thoughts
Credits: Many people are the reason this project came to be. They freely put their knowledge, models, and data in a easy-to-manage and understand format for everyone to use. They deserve a big thank you! They did not in any way participate in this project and cannot be held accountable for anything related to this project.
- Leon Derczynski & Manuel R. Ciosici, ITU, Copenhagen: For sharing such an amazing, large collection of Danish text for NLP development with Gigaword.dk.
- Anita Ågerup Jervelund, dsn.dk: For sharing her knowledge on spelling and grammar mistakes in danish primary/high schools in this amazing report
- certainly.io, Certainly, Malte Højmark-Bertelsen: For developing and training a widely available Danish BERT for the Danish NLP community.
I'm not sure anyone will get this far in my post. If you did, I truly hope you found it valuable! Should you have any questions, then please reach out to me. Best of luck in the future!